Be yourself; Everyone else is already taken.
— Oscar Wilde.
This is the first post on my new blog. I’m just getting this new blog going, so stay tuned for more. Subscribe below to get notified when I post new updates.
Be yourself; Everyone else is already taken.
— Oscar Wilde.
This is the first post on my new blog. I’m just getting this new blog going, so stay tuned for more. Subscribe below to get notified when I post new updates.

We humans are capable of recognizing and interpreting categories/tags such as Person, Location, Date, Time etc of words given in a particular sentence or paragraph. This has proved to be a great boon for humanity in communicating with each other. This helps us in improving teamwork skills and efficiency in completion of the job.
So how great will it be if our highly intelligent computer machines would replicate our human mind tendencies to interpret a high level language such as English. To implement this we take use of computer’s Natural Language Processing(NLP) techniques to analyze natural languages. This involves techniques such as relationship extraction, speech processing, document categorization and summarizing of text. These analytical methods are further based on fundamental techniques such as tokenization, sentence detection, classification, and relationship extraction.
However NLP is a large and complex field. It is a library that includes set of tools mentioned earlier to extracting useful and meaningful information from natural language. To understand working of NLP methods, initially we need to learn our way around commonly used Natural Language terminology, syntax and semantics.
Here syntax refers to rules/boundaries that control the validity of structure present in a sentence that is proper punctuation, spacing, Capital Letters, sentence formation etc. For example consider a sentence “Joey kicked the ball.” is a proper sentence while “kick ball Joey.” is not.
While Semantics is referred as meaning of the sentence that is referring to previous example is easy for us to understand as it is in English while for a computer it would not be so easy as it deals in low-level language.

Since the introduction of internet, in recent years the amount of unstructured data in form of tweets, blogs, and other various social media has been on a meteoric rise that has lead to variety of problems ranging from text analysis on a Internet search or a user entered text to summarization of multiple text files.
Thus this called for enhancements in text analysing process using different machine learning techniques together providing various applications as follows:

Analyzing natural language by a machine is not so easy. There are several constraints which are needed to be considered. For example, at abstract level there are hundreds of natural language each having its own rules, while at character level we need to find a way to deal with special characters, punctuations, hyperlinks etc.
Most basic task in NLP is tokenization that is process of breaking up of text into series of words. These words are known as tokens. But with languages like japanese, chinese, hindi etc it is difficult to tokenize. While in english most problems arise due to ambiguity of words for example “Georgia” can be classified as both name and location.
Having talked about NLP now we will move on our core topic that is Named Entity Recognition that is a word processor which classifies text based on person, location, money, time, date etc. This technique finds its application in chat-bots, queries on wikipedia and quora, word prediction like Google search, etc.
This technique can be divided into two parts:
Although tokenization will help us in detecting most of the words however ambiguity of word meanings can lead to failure in classification as seen in example of “Georgia”.
Since machine cannot understand high level languages, we need to break down the text into chunks of words so that machine can understand it easily. The process of breaking down of sentences into array of words is known as Tokenization. To perform most of the NLP tasks discussed earlier we are required to tokenize the text for further analysis.
The simplest technique is to break down the text by identifying words around white spaces as a delimiter known as WhiteSpace Method.
However, Tokenizing the text has its own problems:
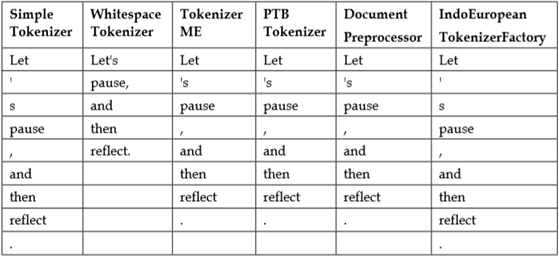
INBUILT JAVA TOKENIZERS
Although these inbuilt methods are less efficient and provide limited amount of support but can be used upto certain extend to our benefit.
We now will compare the two most commonly used methods:
Evaluating both methods we find out that split method was faster and efficient when implemented on collection of large database.
STANFORD TOKENIZERS
Stanford Library has provided a better tokenizer when compared to tokenizers provided by any other library such as OpenNLP, LingPipe.
PTB Tokenizer abbreviated from Penn Treebank(PTB) is one of the most efficient tokenizers available in the market.
Mostly PTB Tokenizer is popular because of its three argument field input providing user control to change limiter to his/her advantage. First argument uses a Reader object i.e. the text paragraph, then comes token factory argument followed by a string to specify different functionality[1] such as controls to handle quotation, or difference between American English and British English, etc.
Language modelling is one the most important topics of Natural Language Processing. The aim of language modelling is to assign a probability to a sentence. Language modelling can be useful in machine translation, Spelling correction, speech processing, summarization, question-answering etc.
The language model computes the probability of a sentence or sequence of words. The probability of a sentence containing n words can be computed as shown in the below equation.
P(A1,A2,A3,A4,…An-1,An)
This is related to the task of computing the probability of upcoming word as
P(An|A1,A2,A3,A4,…An-1)
A model that computes either of the above given probabilities is called a language model or it could be said as grammar because it technically tells us that how good these words fit together. The language model relies on the chain rule of probability which is given by the equation.
P(A1,A2,…,An)= P(A1)P(A1|A2)P(A1|A2∩A3)…P(A1|A2∩A3…An-1) …(1.1)
or we can represent the equation 1.1 as
P(A1,A2,A3,…,An) =i P(Ai|A1A2A3A4…Ai-1)

The probability for a language model can be computed by counting the number of time a particular word occurs after a given sentence conditional to number of times that sentence occurs. As there are too many sentences in English language this method fails because there is not enough data to see the counts of all possible sentences.
Andrei Markov stated that “For a given present situation, the future is not dependent on past” or mathematically we can generalize that
P(Ai|A0,…,Ai-1)=P(Ai|Ai-k…Ai-1) …(1.2)
More formally the markov assumption says that the probability of a sequence of words is the product of each word is the conditional probability of that word, given some prefix of the last few words.
The simplest case of Markov model is the unigram model in which we compute the probability of whole sentence by multiplying the probabilities of individual words. Words are independent in this model and hence the sentence formed doesn’t makes sense because the upcoming word is not related to the previous word.
We estimate the probability of the upcoming word given the entire prefix from the beginning to the previous word just by looking at the probability of the previous word. The sentences formed would make a little bit more sense but still it is useless.
The bigram probability could be estimated by the following equation
P(Ai|Ai-1) =n (Ai-1,Ai)n(Ai-1) …(1.3)
The probability of word Ai given previous the word Ai-1 is counted as number of times words Ai and Ai-1 occur together divide by number of times word Ai-1 occurs.
We can extend the Bigram Model to Trigram, 4-Gram and 5-Gram models. Although language has long distance dependencies, the higher models like Trigram, 4-Gram and 5-Gram will turn out to be just constraining enough that in most cases no problems would occur.
There is an issue of arithmetic underflow because too many small probabilities are multiplied so in practice log of all the probabilities is used and also there is a benefit of using log and that is, the probabilities are in multiplication always and by applying log the terms convert to addition instead of multiplication.
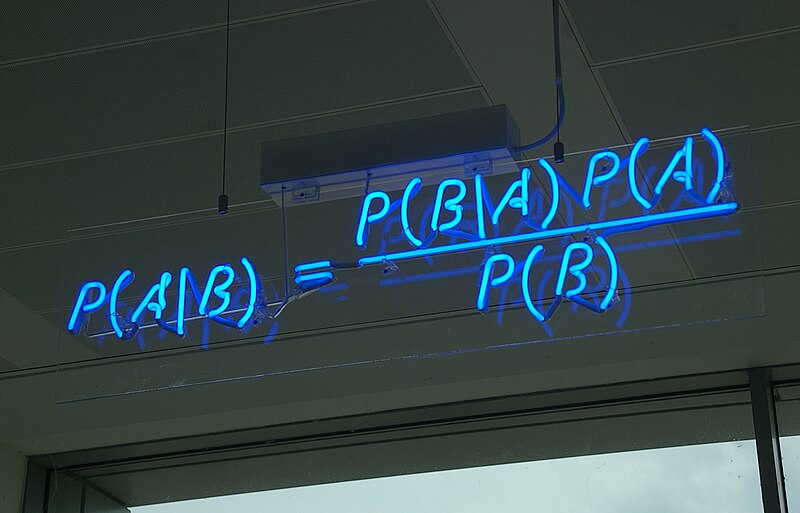
Bayes Theorem can be stated as the probability of B where A has already occured equals probability of A conditional to B times probability of B divided by probability of A.
P(B|A) = P(A|B)×P(B)P(A) …(1.4)
Naive Bayes algorithm can be used for text classification. Suppose if we have a document d and a fixed set of classes C = {c1,c2,c3,…,cj} which in case of named entity recognition can be person, location and organization. A training set of m documents which have been hand-labelled which maps like (d1,c1),…,(dm,cm) which means that document one maps to class one and so on.
Given the set of classes and documents corresponding to that classes and training sets, in output we get a learned classifier Ɣ:d→c where Ɣ is a function which takes the document d and return class c.
Naive bayes algorithm is based on the representation called bag of words representation. The document is inserted to the function and the class is returned such as Person, Location and Organization. The formalization of Naive Bayes for classes and document can be done as follows. P(c|d) gives the probability for each class where we are given a particular document.
P(c|d) = P(d|c)×P(c)P(d) …(1.5)
Putting different values of c where we get the maximum probability is the mapped class. The probability should be maximum which means the numerator of equation 4.5 should be maximum because the denominator is constant for a particular given document.
Class = max(P(d|c)×P(c) …(1.6)
c∈C
The term P(c) means that how often a class occurs which is relatively easy to compute. For example how likely it is for a sentence to begin with LOCATION as compared to PERSON. For P(d|c) there are lot of parameters. Whole document is to be scanned and the probability of each word in the given class is to be computed where there are multiple classes. The maximum value is selected keeping the different values of classes. For example how likely is word “Joe” can classified in the class PERSON, LOCATION or ORGANIZATION. The maximum value of the probability will be when we use class PERSON. However there will a little value when we use other two classes.
Assumptions of Naive Bayes Algorithm:
Certain parts of text can be classified without using any statistical model or training data set. These method is known as Regular Expressions or sometimes abbreviated as RegEx.
Regular Expression is the most basic task for Text Processing and Natural Language Processing. Regular Expression is the formal language which is supported almost all programming languages. It is used for searching a string which follows a particular pattern for example searching all numbers in a text, particular substring containing alphabets and special characters, all capital letters in the text etc. and many more.
Regular Expression can be very useful for classifying Dates, URLs, Emails, Time and Percentage. All the examples shown always follow a pattern for their format. There is a particular we have to enter into Pattern compiler and after that the Matcher function matches all the substrings that follows that particular pattern.
Some of the famous regular expressions are shown in the Image 5.1


The models which we looked so far such as Naive Bayes model or Language model are “generative models” but now there is much use of “discriminative models” or “conditional models”. The reason is high accuracy and much more features could be included.
Joint models places probability over both the class and document which mean probability of P(c⋂d). Generative models observe data from the hidden classes.
Discriminative models or Conditional model directly targets the classification decision. They use probability distributions that are conditional P(c|d) which means probability of a class given the data. Discriminative models include Logistic regression models, conditional log linear models, maximum entropy models or conditional random field models.
The circles in the figure 5.2 indicates the random variable and the lines show the dependencies. Imagine that the Y in the figure 4.1 is the set of classes and x1, x2 and x3 are data. Here the task of predicting Y is done. Here all the xi are very correlated with each other and also contains redundant information. If we represent the above scenario in naive bayes model the same feature is counted again and again. While in case of CRFs there is no need of computing distributions over x. It uses conditional probability in which x has already occurred and we find the probability of occurrence of y.
Here we represent a feature as f function with a bounded real value which takes data d as input and c as output. Let us take two example
features.
f1(c,d) ≡ [c = LOCATION ∧ w-1 = “in” ∧ isCapitalized(w)]
f2(c,d) ≡ [c = LOCATION ∧ hasAccentedLatinCharacter(w)]

The feature will ask some questions related to task and some questions related to the sequence of words. Here as we can see that the feature picks out the class LOCATION when the particular entity belong to LOCATION class as well as satisfies the conditions where the previous word should be in and the first letter of the word should be capital.
Next thing is the model will assign each feature a weight which is a real number. Suppose there are three data for testing and they are “in Arcadia” , “in Québec” and “saw Jack”. The weight to the first two words will be assigned positive and that of the last one would be negative because it does not satisfy any of the condition. Each feature picks out the data set and assign label and weight to it.
Information Extraction is used to find structured information from a given part of text. The goal of Information Extraction is to organize information which can be interpreted easily. Second goal is to put information in an organized manner for computers which allows further interferences to be made by computer algorithm.
The kind of Information the IE systems can extract is Name of a person, Location, Organization, Time, Money, Percentage etc. A very important sub-task of Information Extraction is Named Entity Recognition.
First of all we need to tokenize the text using any one of the method discussed earlier and then categorize it with CRF classifier into categories of person, location, or organization, etc.
Consider the following sentence being tokenized and classified by two different schemes:

IO(Inside-Outside) Encoding is a simple classifying procedure in which as you can observe Mengqui Huang being a single name are being identified as two different names which is unacceptable.
However in contrast to IO we now look upon a far complex and slower IOB(Inside-Outside-Beginning) Encoding which denotes an entity’s starting word as B-tag denoting beginning while an I-tag to words that have same entity class of the preceding word depicting a continuation in the entity.
This systems can further be improvised using a Machine Learning Algorithm that can accurately derive word-entity relationships efficiently.
NLP is one of the most exciting area in computer science sector that involves working with high level language. The variety it offers in terms of innovation beyond any imagination. NER being presented as a core topic to work on was challenging as well as exciting. We came know about various techniques to tokenize and classify various forms of unstructured data into well established relationship of word and it’s entity.
After working on a small section of a broad technical area of NLP, we came know about the true potential NLP has to offer. With the advancements being made in Artificial Intelligence Sector there is huge potential need for more advanced NLP algorithms to make our systems compatible with high level languages easing our communication with the machines.
Voice Recognition System as well as text-to-speech based systems can take a huge help from NLP techniques to implement their ideas.

Internet has become widely popular nowadays and it is also growing as a source of information. In this era of growing information on the internet there is much need of organizing the data which is available publicly and analyze it. Scraping according to the definition means collecting or accumulating something with great difficulty and web scraping means collecting or accumulating web data. Web Scraping is nothing but extracting data from web which can be easily read and organized by humans. The data which is to be scraped is available publicly and it does not contains private data like user’s information in most of the cases.
There are various tools available for web scraping among which the one discussed in this paper are “Nokogiri” and “Kimono”. Nokogiri is a programming based web scraping tools and Kimono is GUI based web scraping tool.
Web Scraping is about getting a particular data which is scattered among many web pages or many tables or many tags all around the internet. Web Scraping means accessing all the HTML data from a given webpage and sometimes more than just HTML. Web Scraping is easy to learn and implement using programming languages while there are some softwares available in the market which does the work of programming and user just have to enter the details regarding which data to scrape.
In general to access a webpage we need to access the web through HTTP (HyperText Transfer Protocol) or through web browser by creating an agent which behaves like web browser.
There are certain ways we can process data after scraping
The general method of scraping consists of accessing the website through HTTP using the methods which are available in the language library. Then the user visits the website once to look at the structure of the website. To see the structure of the website the user uses developer tools like Inspect Elements in Google Chrome. He/She observers clearly the part which is to be scrapped. Next he/she finds something unique in that tag like its class or id and he/she can get the text from that tag by searching using the unique class or id from the parsed data. This is a general procedure for scraping the data using HTML. However another methods for web scraping includes usage of xpath selectors. They are generally used for XML.
Web scraping in general can be used to analyze a particular type of data from different websites. Some of the applications of Web Scraping are:-

Nokogiri is a gem (library) of Ruby programming language. A gem or library means providing additional features to a programming language and Nokogiri does that. Nokogiri is one of the most downloaded Ruby gem. Ruby and Nokogiri creates scraping using programming very easy for the users.
Nokogiri takes a url in input as an argument in open() method which comes in open-uri gem of ruby. The method is returned as an object of Nokogiri class which contains the parsed data. Now suppose the name of the object which contains the parsed data is obj, obj contains methods such as at_css() or css() which takes class or id as argument and returns the whole tag in string form. Further using .text after at_css() gives only the text on that tag.
There is another method that is used to scrape data and that is xpath() method. Instead of taking class or Id name in tag it takes the name of HTML tag or XML tag and if we want to go inside a particular tag, the path is separated by using “//”. It returns the same string as we get using at_css() method. The only difference between both the methods is the searching methods for both the methods[3].
Nokogiri is fast and efficient. It is made by combining the powers of raw power of native C parser Libxml2 and Hapricot .
The main competitors of Nokogiri are Beautiful Soup which is a library of Python and rvest which is library of R.
Nokogiri is well documented so it is easy for beginners to learn. As compared to other web scrapers, Nokogiri can deal with broken HTML, which is a drawback of web scraping, while other scrapers cannot deal with broken HTML easily.
The only disadvantage of Nokogiri is that Ruby lacks machine learning and NLP libraries and hence the data cannot be processed properly.

#! /usr/bin/env ruby
require 'nokogiri'
require 'open-uri'
# Fetch and parse HTML document
doc = Nokogiri::HTML(open('https://nokogiri.org/tutorials/installing_nokogiri.html'))
puts "### Search for nodes by css"
doc.css('nav ul.menu li a', 'article h2').each do |link|
puts link.content
end
puts "### Search for nodes by xpath"
doc.xpath('//nav//ul//li/a', '//article//h2').each do |link|
puts link.content
end
puts "### Or mix and match."
doc.search('nav ul.menu li a', '//article//h2').each do |link|
puts link.content
end
To know more about Nokogiri, https://nokogiri.org/

Kimono is a GUI based chrome extension for web scraping. It is robust, automated and easy to use web scraper. It also allows the user to create an API and use it further. The fields are calibrated automatically and detects automatically what the user might want to scrape. The user can also confirm or deny the suggestive listing which is automatically done by kimono.
One of the unique feature of kimono is that it shows the unique breakdown code of HTML which could also be used as argument to different functions in the functions in programming based web scrapers. It also gives regular expression of the thing which user is trying to find. Pagination is also supported in Kimono which means the user can scrape pages of pages. Kimono also gives features of automated crawling which means that it updates the data after every particular time selected by the user. The crawl limit of Kimono is only 25 pages.
DRAWBACKS OF KIMONO
To start with Kimono check out https://www.youtube.com/watch?v=8D9gGxS1_qg
Web scraping is extracting data and convert the data from human readable to the language which could be understood by machines and programming languages. In other words converting into a structured data which could be processed easily. There are two types of tools for Web Scraping first is programming based and second is GUI based. Nokogiri is very famous programming based web scraping environment while Kimono is famous GUI based web scraping chrome extension.
Web Scraping is very important skill to learn in the world where there is so much popularity of Data Science. Collecting data is one of the primitive steps of Data Mining and Data Processing. Various tools for Web Scraping are discussed here according to the need of the user.
